Application Security — The Complete Guide

What is application security (AppSec)?
Application security is an essential part of the software development lifecycle, and getting it right should be a top priority in today’s ever-evolving and expanding digital ecosystem. Application security is the practice of protecting your applications from malicious attacks by detecting and fixing security weaknesses in your applications’ code.
Organizations today invest a lot of time and money in information security tools and processes that help them secure their applications throughout the software development lifecycle. Achieving application security has become a major challenge for software engineers, security, and DevOps professionals as systems become more complex and hackers are continuously increasing their efforts to target the application layer.
How can software development organizations make sure that they have all the tools and processes in place to effectively address the many threats to application security?
Why is application security important?
Application security is important because applications remain the weakest security link. Findings from top industry research reports show that attacking application weaknesses and software vulnerabilities remains the most common external attack method. For example, Verizon’s 2022 Data Breach Investigations Report found that web applications are the top hacking vector in breaches.
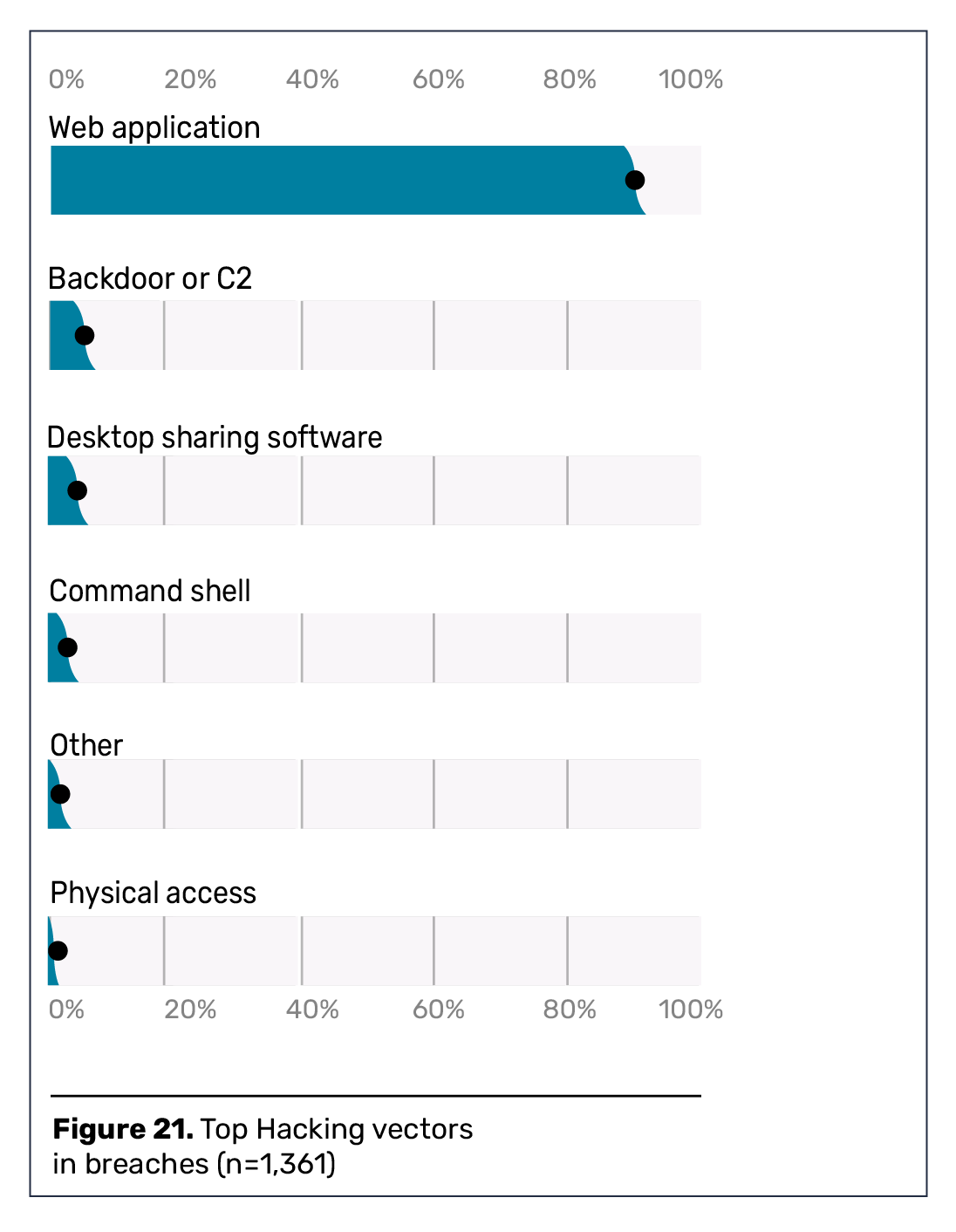
Forrester’s 2022 State of Application Security Report also revealed that application and software vulnerabilities continue to be the most common external attack vectors, along with software supply chain breaches.
Unfortunately, it appears that most organizations continue to invest in the protection of other attack vectors. Currently, the amount of investment in protecting certain areas like the network is often inconsistent with the level of risk associated with them in today’s threat landscape.
According to the Ponemon Institute’s Research Report, The Increasing Risk to Enterprise Applications, “Investment in application security is not commensurate with the risk.” The research report shows that “There is a significant gap between the level of application risk and what companies are spending to protect their applications,” while “the level of risk to networks is much lower than the investment in network security.”
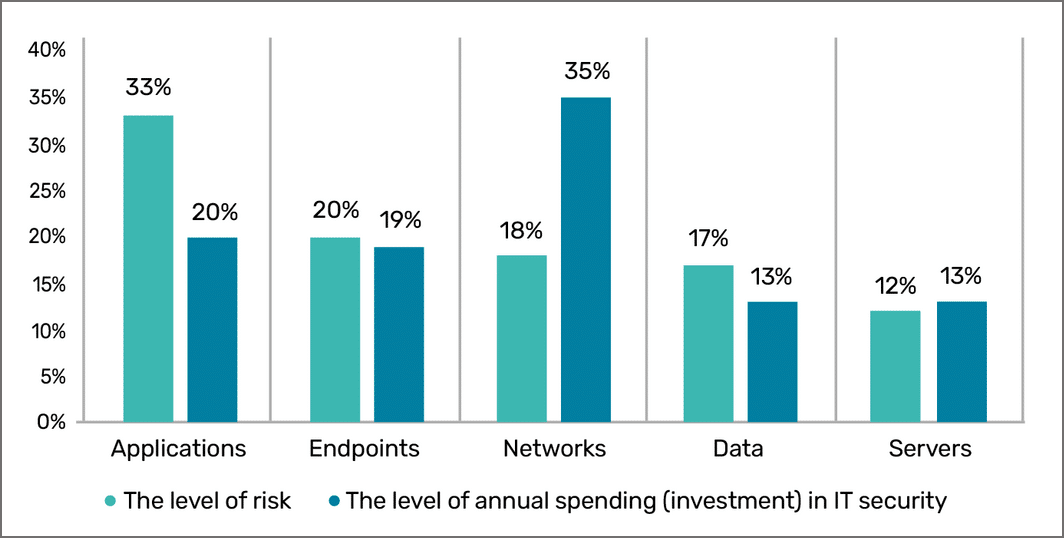
In order to ensure effective application security, organizations need to make sure that their application security practices evolve beyond the old methods of blocking traffic, and they should understand that investing heavily in network security is not enough.
Significant trends in application security
Application security is growing in importance because more and more applications are being developed all the time. The source of these applications is an escalating volume of code, both open source and custom, which can be the breeding ground for vulnerabilities that pose increasingly serious security threats if they aren’t addressed properly with AppSec automation strategies and tools. In short, the attack surface continues to grow and the risks grow with it.
Perhaps the most significant example recently is the widespread exploitation of a critical remote code execution (RCE) vulnerability (CVE-2021-44228) in Apache’s Log4j software library that was discovered at the end of 2021. At the time of its discovery, the director of the United States Cybersecurity and Infrastructure Security Agency (CISA), Jen Easterly, said:
“Log4j vulnerabilities present a severe and ongoing threat to organizations and governments around the world . . . These vulnerabilities are the most severe that I’ve seen in my career, and it’s imperative that we [the public and private sectors] work together to keep our networks safe.”
Almost a year later, this threat hasn’t gone away. A joint alert by CISA and the FBI recently warned that federal networks could still be compromised by malicious actors exploiting this vulnerability.
Consequently, governments and legislatures throughout the world have responded to this challenging environment by establishing guidelines, directives, and acts to mandate the implementation of application security measures. For example, in 2021, the White House issued Executive Order (EO) 14028, entitled “Improving the Nation’s Cybersecurity,” which focuses on the security and integrity of the software supply chain and emphasizes the importance of secure software development environments. In 2022, the Executive Office of the President of the United States issued a further memorandum for the heads of U.S. Government and Federal executive departments and agencies, which lays out guidelines for reinforcing the security of the software supply chain through secure software and application development practices.
This demonstrates that application security has become a significant issue at the highest level, and something that organizations, both public and private, are advised to address as a priority.
How does application security work?
Typically, the approach that’s taken to assure application security is the process laid out in the Cybersecurity Framework (CSF) published by the United States National Institute of Standards and Technology. In short, this approach, or methodology, is as follows:
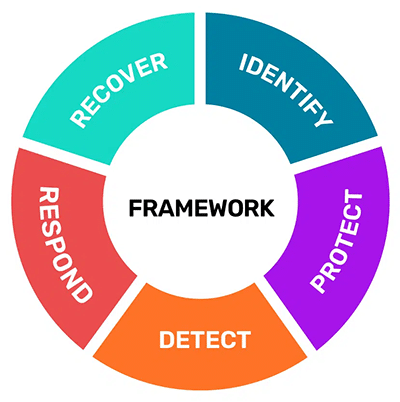
Source: https://www.nist.gov/cyberframework
- Identify security risks
- Protect, by security testing and applying the right tools to safeguard your code, applications, data and systems
- Detect, which involved employing the tools to find and alert you to threats and vulnerabilities
- Respond, by taking the necessary action to stop or minimize any flaws, vulnerabilities or threats when they have been detected.
- Recover, by mending any issues that arise and restoring regular operational capabilities.
The application security process involves applying measures that can identify new or anomalous code, detect whether it’s vulnerable, and fix vulnerabilities before they expose you to infiltration or attack. A combination of types of security testing and different security testing tools, detailed below, are employed to find and mend vulnerabilities throughout the software development lifecycle, so that any unauthorized access to your applications, data or source code is prevented.
Types of application security testing
The methodology outlined above, indeed any comprehensive application security strategy, requires you to assess and safeguard a host of different applications that, generally speaking, are mobile applications, Cloud-based, or web-based. To cover them all involves implementing application security measures for each type, as they differ in how they take place. Broadly, they are as follows:
- Mobile application security is designed to assess the risk of applications that run on mobile platforms for phones and tablets, particularly Android, iOS, and Windows Phone. It assesses apps for vulnerabilities based on the environments in which they run and identifies problems that might arise from user behavior. Testing is done by taking the role of a hacker or malicious actor and attempting to attack apps. Mobile app security combines static and dynamic analysis and penetration testing.
- Cloud application security focuses on securing applications in cloud environments, with an emphasis on managing access, data protection, infrastructure security, logging and monitoring, incident response, and vulnerability mitigation and configuration analysis. There’s a strong element of policy and process implementation here.
- Web application security involves ensuring that security controls are built into websites to protect them from attacks, and identifying and fixing application design flaws and bugs, This is achieved by scanning for vulnerabilities, updating code and where possible, remediating vulnerabilities, by applying application security tools and solutions throughout the software development lifecycle, such as SAST (static application security testing), DAST (dynamic application security testing), IAST (interactive application security testing), SCA software composition analysis, penetration testing and runtime application testing (RASP).
Application security tools and solutions
When it comes to investing in application security tools, the market offers a variety of solutions to help organizations improve their application security and ensure it keeps up with the challenges of the evolving threat landscape.
Forrester’s market taxonomy for application security tools makes a distinction between two market segments: application security scanning tools and runtime protection tools and predicts that spending will continue to rise for both categories.
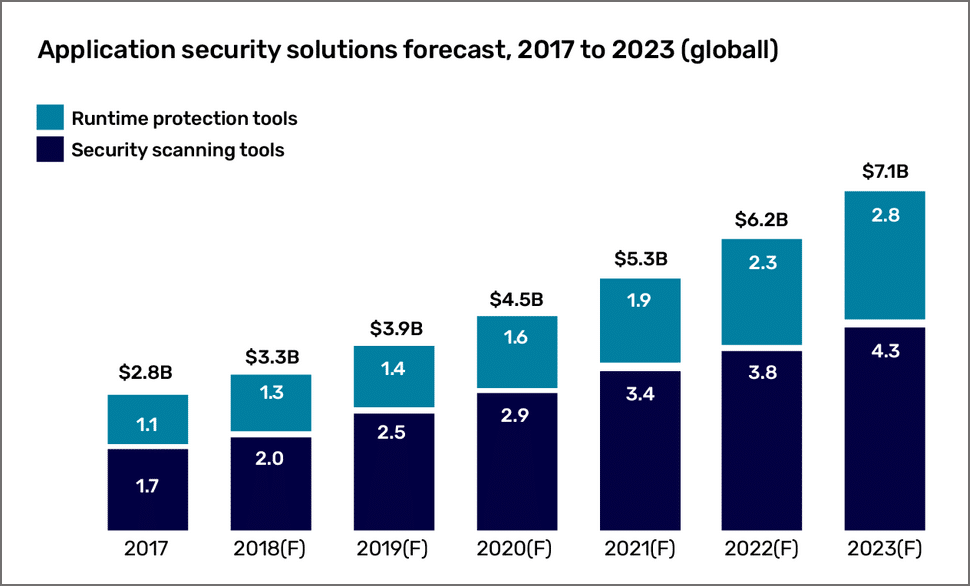
Each category of application security testing tools focuses on a different stage in the software development lifecycle. Security scanning tools are used to remediate vulnerabilities when applications are in development. Runtime protection is performed when applications are in production. It’s important to remember that runtime protection tools provide an extra layer of protection and are not an alternative to scanning.

Security scanning tools are used primarily in development — applications are tested in the design and build stages. The goal of security scanning tools is prevention. They detect and remediate vulnerabilities in applications before they run in a production environment. Tools in this market include SAST (static application security testing), DAST (dynamic application security testing), IAST (interactive application security testing), and software composition analysis. Gartner defines SAST and DAST as follows:
SAST is a set of technologies designed to analyze application source code, byte code and binaries for coding and design conditions that are indicative of security vulnerabilities. SAST solutions analyze an application from the “inside out” in a non-running state.
DAST technologies are designed to detect conditions indicative of a security vulnerability in an application in its running state. Most DAST solutions test only the exposed HTTP and HTML interfaces of Web-enabled applications. However, some solutions are designed specifically for non-Web protocol and data malformation (for example, remote procedure call, Session Initiation Protocol [SIP]).
IAST is an application security testing (AST) tool designed for modern web and mobile applications that works from within an application to detect and report issues while the application is running. IAST was developed as an attempt to overcome some of the limitations of SAST and DAST. Like DAST, testing occurs in real time while the application is running in a QA or test environment. Unlike DAST, however, IAST can identify the problematic line of code and notify the developer for immediate remediation. As with SAST, IAST also looks at the code itself, but it does so post-build, in a dynamic environment through instrumentation of the code. IAST can be easily integrated into the CI/CD pipeline, is highly scalable, and can be automated or performed by a human tester.
Software Composition Analysis (SCA) manages open source component use. SCA tools perform automated scans of an application’s code base, including related artifacts such as containers and registries, to identify all open source components, their license compliance data, and any security vulnerabilities. In addition to providing visibility into open source use, some SCA tools, like Mend SCA, also help fix open source vulnerabilities through prioritization and auto-remediation.
Runtime protection tools come in later in production. They are designed to protect against malicious players while an application is running in a production environment. These tools react in real-time to defend against attacks. This market is segmented into web application firewalls (WAF), bot management, and RASP (runtime application self-protection).
Each one of these application security testing technologies has its own set of features and functions, and its strong and weak points. No single tool can be used as a magic potion against malicious players. Organizations need to analyze their specific needs and choose the tools that best support their application security policy and strategy.

Getting it right: Application security best practices
While getting the right tools for application security is important, it is just one step. Though most tools today focus on detection, a mature application security policy goes a few steps further to bridge the gap from detection to remediation.
Considering the continuous increase in known software vulnerabilities, focusing on detection will leave organizations with an incomplete application security model. Application security tools often provide security and development teams with exhausting laundry lists of security alerts. However, teams also need to have the means to quickly fix the issues that present the biggest security risks.
In order to address the most urgent application security threats, organizations need to adopt a mature application security model that includes prioritization and remediation on top of detection.
While detecting as many security issues in the application layer is extremely important, considering the current threat landscape and competitive release timelines, it has become unrealistic to attempt to fix them all. It’s important to remember Gartner analysts’ Neil MacDonald and Ian Head’s statement from Gartner’s 10 Things to Get Right for Successful DevSecOps: “Perfect security is impossible, Zero risk is impossible. We must bring continuous risk and trust-based application security assessment and prioritization of application vulnerabilities to DevSecOps.”
A mature application security model includes strategies and technologies that help teams prioritize — providing them the tools to zero-in on the security vulnerabilities that present the biggest risk to their systems so that they can address them as quickly as possible. Otherwise, teams end up spending a lot of valuable time sorting through alerts, debating what to fix first, and running the risk of leaving the most urgent issues unattended.
Next in the application security maturity model comes remediation — technologies that integrate seamlessly into the development cycle to help remediate issues when they are relatively easier and cheaper to fix, and update vulnerable versions automatically.

Application security at the speed of DevSecOps
As development cycles get shorter, security professionals and developers struggle to address security issues while keeping up with the increasingly rapid pace of release cycles. This constant push and pull between application security needs and the speed of development often results in friction between developers who don’t want security to slow them down and security professionals who feel developers are neglecting security. The DevSecOps approach attempts to address this conflict and break the silos between developers and security.
DevSecOps addresses the challenge of continuously increasing the pace of development and delivery without compromising on security. First came DevOps, which helped organizations create shorter release cycles so that they could meet the market demand of delivering innovative software products at a rapid pace. DevSecOps adds security to the mix, integrating security throughout the software development lifecycle (SDLC), to make sure that security doesn’t slow down development and application development is both agile and secure.
DevSecOps aims to seamlessly integrate application security in the earliest stages of the SDLC, by updating organizations’ application security practices, tools, and teamwork. It calls for shifting security testing left to help teams work together to address security issues early in development when remediation can be relatively simple.
Hackers are also keeping up with the evolving software development landscape
As applications evolve and take on new forms, malicious players adapt to the new technologies and environments. The days of applications being heavy monolithic client/server behemoths are long gone, and your application security strategies need to keep up in order to protect against current threats to your applications.
Attackers compromise modern applications through unsecured API endpoints, unvalidated API payloads, and client-side attacks injecting malware into unprotected scripts. The rise of new architectures like cloud-native and frameworks offers new attack surfaces. Security professionals need to adjust their focus and address issues like image integrity, vulnerabilities in common container images, and changes to containers and functions in production.
Application security is a constantly evolving ecosystem of tools and processes. If you want to stay ahead of the hackers, you need to make sure that your application security practices are the best.
How can Mend.io help with application security?
Mend’s application security platform provides a comprehensive security solution for your entire code base. It includes Mend SAST (static application security testing) for custom code, Mend SCA (software composition analysis) for open source, Mend Supply Chain Defender solutions and Mend Renovate, its dependency update solution.
Mend SAST allows application developers to rapidly design new applications while maintaining the security of their custom code. Clients can evaluate the recommended code changes and approve or disapprove them using a pull request. And the automated remediation feature produces the exact code changes required to resolve code problems.
Mend SCA detects open-source vulnerabilities in over 200 languages, frameworks, and development tools. It provides pull requests with automated remediation, enabling developers to update the recommended open-source package with a single click.
Mend Supply Chain Defender protects against attacks by stopping malicious packages from being installed before they can affect developers, CI (continuous integration) servers, or production.
Mend Renovate automatically resolves outdated dependencies saving developers’ time, reducing risk, and mitigating the impact of security vulnerabilities.
So, when it comes to application security, are you prepared and protected?
Discover the five key principles of modern application security to help you meet the demands of today’s digital ecosystem.
